RoP v2026.04: 1.33 Million Harmonized Biomedical Data Elements - open sourced!
Published: May 13, 2026 Authors: Pietro Marini, Alan Long, Hirotaka Iwaki, Mike Nalls, Dan Vitale (DataTecnica)
What Is RoP?
RoP is 1.33 million harmonized biomedical Common Data Elements with semantic embeddings, value sets, and governance parameters that make multi-cohort research actually interoperable.
RoP is the foundation for The Forge — our automated data and schema harmonization registry with human-in-the-loop validation. Think of RoP as fuel for the harmonization engine.
Right now, multi-cohort studies spend months (often years) manually mapping variables—PPMI calls it “MoCA Total Score,” NACC calls it MOCATOTS, ADNI calls it MOCA. Same assessment, zero automatic compatibility. Multiply this by 500 variables across 10 cohorts, and you’re looking at person-years of manual mapping before analysis even starts.
The cost: Biomedical researchers spend 40-70% of their time on data wrangling and harmonization (Kaggle survey). RoP + The Forge save an order of magnitude in both time and cost for data standardization.
RoP provides 1.33 million pre-harmonized Common Data Elements (CDEs) organized into 13 themes covering every layer of biomedical data—from individual identity and clinical phenotypes to genomics, imaging, governance, and resource catalogs. Built on OMOP, LOINC, ICD-10, HPO, Mondo, and 9 other major vocabularies.
This isn’t aspirational. It’s running in production across hundreds of thousands of samples and multiple millions of data points for collaborators leading massive federated open science initiatives.
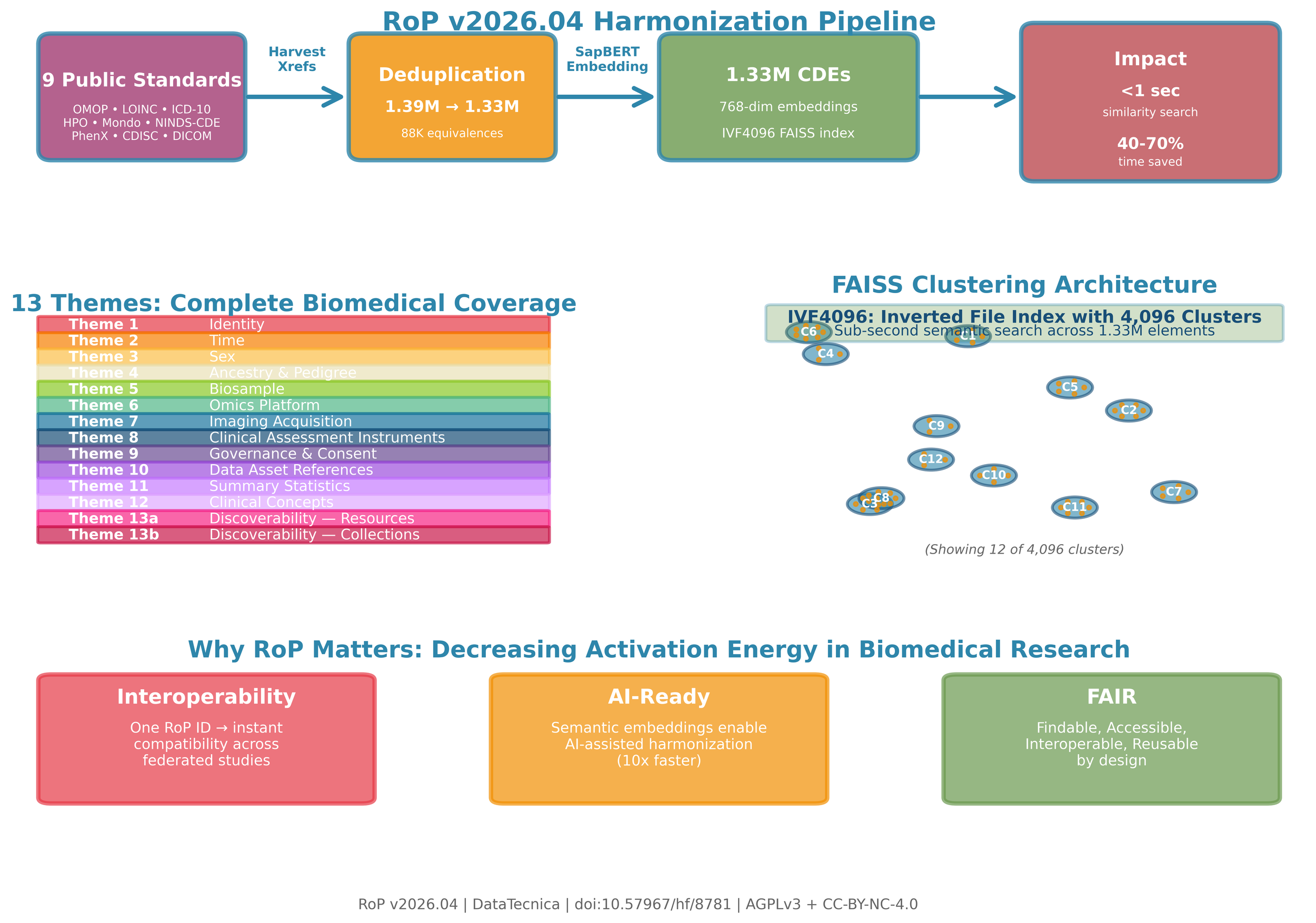
Figure 1: RoP Overview.
Why It Matters
We want to accelerate the biomedical research community. Let’s make research as FAIR as possible.
Multi-cohort research shouldn’t require 6 months of manual variable mapping before the first analysis. RoP solves this by providing a shared reference that enables:
Interoperability: Tag your variable with a RoP ID once → instant compatibility across federated studies
AI-readiness: Semantic embeddings enable AI-assisted harmonization (10x faster than manual)
FAIR principles: Findable (DOI-versioned), Accessible (open download), Interoperable (cross-vocab mappings), Reusable (full reproducibility)
The work behind RoP: Weeks of planning, one weekend of compute, decades of experience. The v2026.04 release represents 6+ person-years of expert harmonization work, distilled into a 7.8 GB download.
What’s Inside
v2026.04/├── elements.parquet 1,328,973 CDEs (151 MB)├── embeddings.npy 768-dim SapBERT vectors (3.9 GB)├── embeddings.faiss IVF4096 similarity index (3.9 GB)└── manifest.json SHA256 checksums + metadataSources: 1,326,063 foundation CDEs from 9 public standards (OMOP, LOINC, ICD-10, HPO, Mondo, NINDS-CDE, PhenX, CDISC, DICOM, BIDS, DUO) + 2,910 boutique CDEs from 9 project collections.
13 Themes: Identity, Time, Sex, Ancestry & Pedigree, Biosample, Omics, Imaging, Clinical Instruments, Governance, Data Assets, Summary Stats, Clinical Concepts, Discoverability (Resources + Collections).
Get RoP
📥 Download the data: Hugging Face Dataset (7.8 GB, DOI: 10.57967/hf/8781)
💻 Get the code & full documentation: GitHub Repository (build from source, reproducible pipeline)
🔨 Get help using RoP with The Forge: Submit Interest Form (AI-assisted harmonization, governance enforcement)
✏️ Suggest CDE additions or corrections: Schema Feedback Form
Community & Open Science
Primary Authors: Pietro Marini, Alan Long, Hirotaka Iwaki, Mike Nalls, Dan Vitale
Collaborators: Mette Peters, Hampton Leonard, Andy Henrie, Amara Alexander, Elise Marsan, Yang Fann, Mark Cookson, Cornelis Blauwendraat, Andy Singleton, Huw Morris, Tim Hohman, Sara Biber, John Crary, Syed Shah, Brittany Dugger, David Gutman, Chris Morris, Pat Brannelly, Liesel Jones, Mat Koretsky, Cole Tindall, Mukta Phatak, Zane Jaunmuktane, Mimi Tambi, Brandon Jernigan, Terri Thompson, Mike Karlovich, Kurt Farrell, and many more… CDEs are a community effort, we really hope to get some of these to the NLM’s amazing catalog as well (they have done decades of some of the most influential work in this space).
Collaborative Studies: NIH CARD, GP2, NACC, Answer ALS, SEA-AD, ADSP-PHC, ASAP, BDR, BDSA, PART through their connection with the Path-ND Consortium by the 10,000 Brains Project
Upstream Standards: OHDSI (OMOP), Regenstrief (LOINC), Monarch Initiative (HPO, Mondo), NIH (NINDS-CDE, PhenX), CDISC, GA4GH (DUO), DICOM, BIDS
Foundational Concepts: This work is based on the preprint by Long et al 2024 (https://pubmed.ncbi.nlm.nih.gov/39484274/), hopefully in press very soon.
Built with 🔨 by DataTecnica | datatecnica.com