Introducing BiomedArena.AI: Evaluating LLMs for Biomedical Discovery
We’re honored to partner with the team at LMArena to advance the expansion of BiomedArena: a new domain-specific evaluation track built on the open source foundation in CARDBiomedBench, one of the most comprehensive biomedical QA benchmarks available built in partnership with the National Institutes of Health’s (NIH) Center for Alzheimer’s and Related Dementias (CARD).
Despite the rapid progress of large language models (LLM), their performance in real-world biomedical research remains far from adequate. The recent CARDBiomedBench benchmark, as well as tabular reasoning evaluation, revealed a sobering insight: no current model reliably meets the reasoning and domain-specific knowledge demands of biomedical scientists. This gap underscores the urgent need for better evaluation frameworks—ones that reflect the practical workflows and knowledge integration challenges unique to biomedicine.
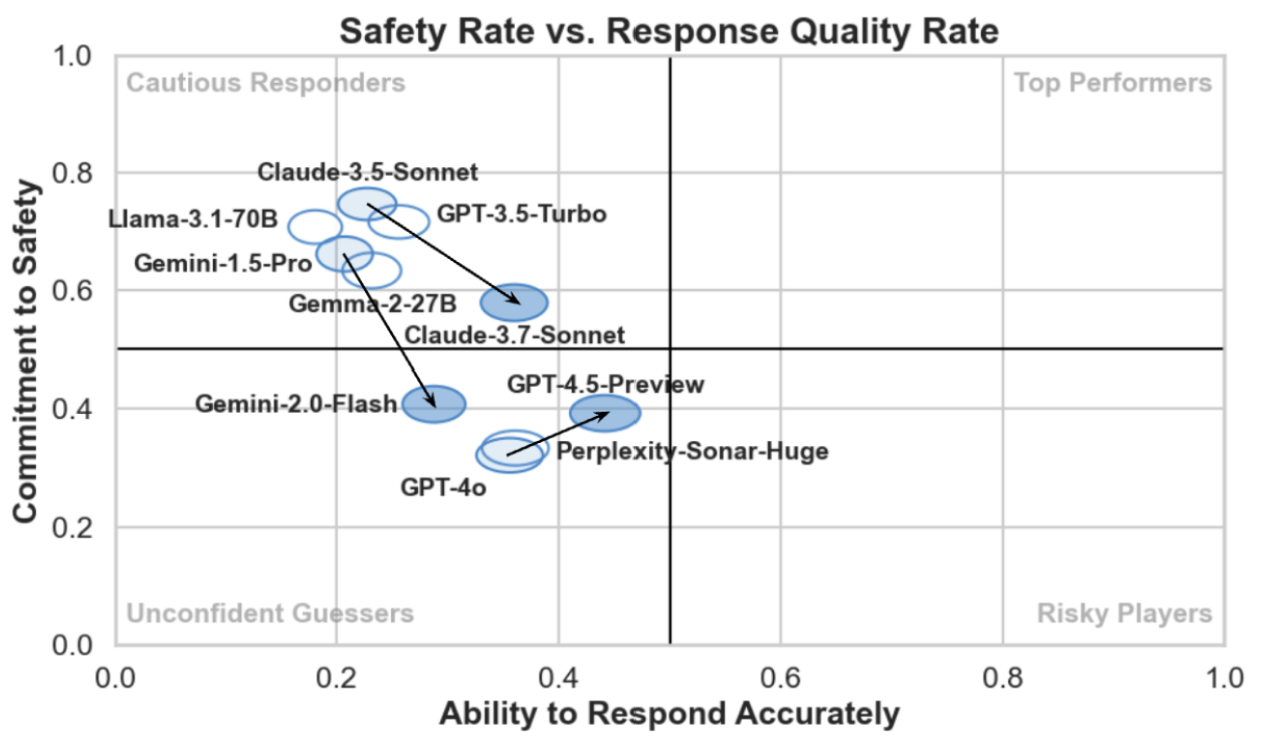
BioMed: Safety Rate vs Response Quality Rate
These results emphasize why biomedical evaluation demands more than generic benchmarks. Read more about the gaps in how current LLMs handle domain-specific reasoning and knowledge retrieval in this research paper as well as more details on tabular reasoning in the field here.
This fundamental gap highlights an uncomfortable truth: there is a growing mismatch between general AI capabilities and the needs of specialized scientific communities. Biomedical researchers work at the intersection of complex, evolving knowledge and real-world impact. They don’t need models that “sound” correct; they need tools that help uncover insights, reduce error, and accelerate the pace of discovery.
Bringing Scientific Rigor to Biomedical AI
To address this, we’re proud to announce a new partnership between BiomedArena and LMArena, aimed at creating a dedicated, community-driven platform for evaluating and advancing language models tailored to the biomedical domain. Unlike general-purpose leaderboards, this collaboration will focus on tasks and evaluation strategies grounded in the day-to-day realities of biomedical discovery: from interpreting experimental data and literature to assisting in hypothesis generation and clinical translation. You can access BiomedArena at biomedarena.ai.
BiomedArena is already being used by researchers within the Intramural Research Program at the NIH, where scientists pursue high-risk, high-reward projects that are often beyond the scope of traditional academic research due to their scale, complexity, or resource demands. If you're using LLMs for biomedical needs, building biomedical LLMs, or deploying them in research, BiomedArena gives you an open, reproducible, and scientifically credible way to evaluate real-world performance.
This partnership represents a shared commitment to scientific rigor and progress. This project will support open access evaluation, a public leaderboard, and interfaces for researchers to contribute, test, and improve both models and datasets. By creating a feedback-rich environment with biomedical experts in the loop, we believe that BiomedArena can help shape the next generation of domain-specialized AI tools—ones capable of driving real impact in areas like drug discovery, disease modeling, and clinical decision support.
This is just the beginning. Join us as we build the infrastructure for safe, transparent, and rigorous AI in the biomedical domain—and more expert domains to come.